Bert 模型的细节到底是怎么样的,对于论文中的提到的4个下游任务场景到底是怎么进行数据集构造以及模型微调的?预训练任务的数据集又是怎么构造的,模型应该怎么实现?
BERT是一种预训练语言模型(pre-trained language model, PLM),其全称是Bidirectional Encoder Representations from Transformers(双向编码表示)。
语言模型 是这样一个模型:对于任意的词序列,它能够计算出这个序列是一句话的概率。比如词序列A:“知乎|的|文章|真|水|啊”,这个明显是一句话,一个好的语言模型也会给出很高的概率,再看词序列B:“知乎|的|睡觉|苹果|好快”,这明显不是一句话,如果语言模型训练的好,那么序列B的概率就很小很小。
下面给出较为正式的定义。假设我们要为中文创建一个语言模型, V 表示词典, V={ 猫,狗,机器,学习,语言,模型,…}, 。语言模型就是这样一个模型:给定词典 V,能够计算出任意单词序列
,是一句话的概率 p (
) ,其中p>0。——摘自语言模型的概念
预训练:预训练是一种迁移学习的概念。所谓预训练模型,举个例子,假设我们有大量的维基百科数据,那么我们可以用这部分巨大的数据来训练一个泛化能力很强的模型,当我们需要在特定场景使用时,例如做医学命名实体识别,那么,只需要简单的修改一些输出层,再用我们自己的数据进行一个增量训练,对权重进行一个轻微的调整即可。预训练语言模型有很多,典型的如ELMO、GPT、BERT等。
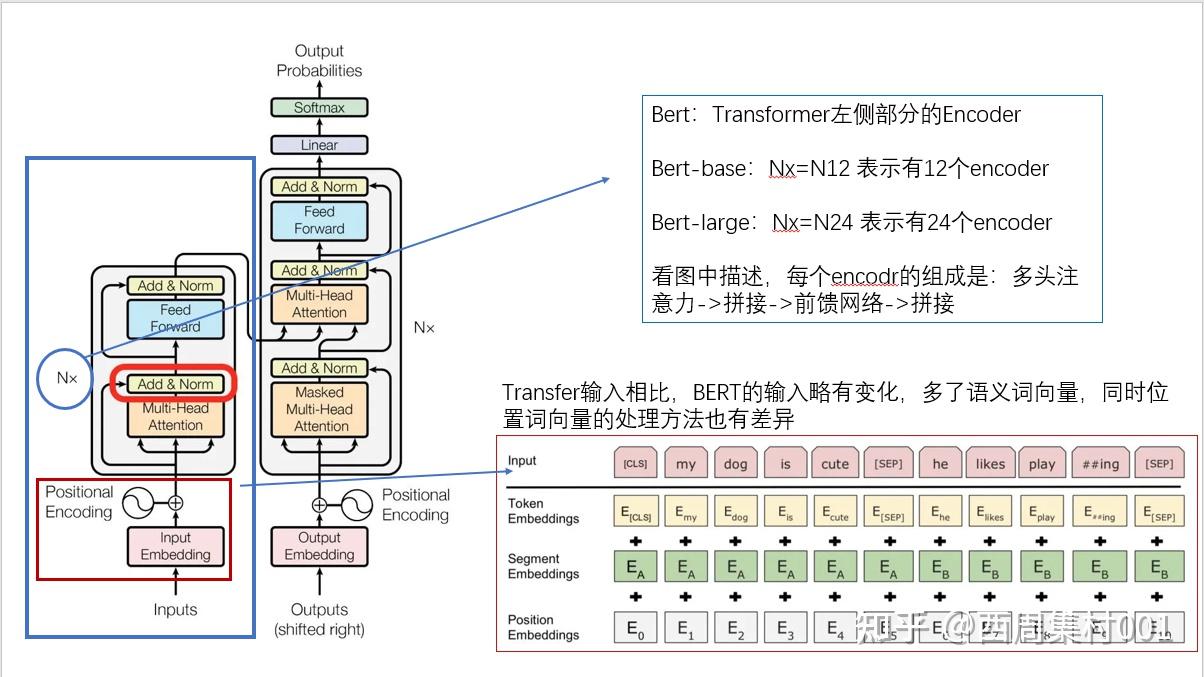
Bert是基于Transformer实现的,BERT中包含很多Transformer模块,其取得成功的一个关键因素是Transformer的强大作用。可以参考:手推transformer_哔哩哔哩_bilibili
因为BERT之前的预训练语言模型如ELMO和GPT都是单向的(ELMO可以说是双向的,但其实是两个方向相反的单向语言模型的拼接),而结合上下文信息对自然语言处理是非常重要的。Bidirectional也是Bert的主要创新点。
REF: BERT详解:概念、原理与应用
BERT模型微调之后可以做自然语言处理相关的任务,
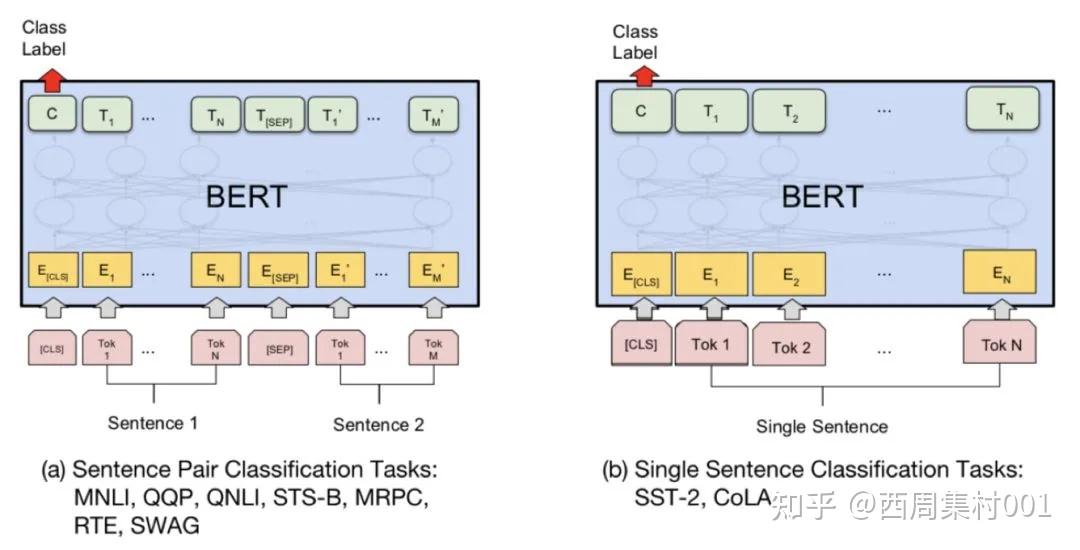
句子对分类任务:给定一对句子,目标是预测第二个句子相对于第一个句子是包含,矛盾还是中立的;
单句子分类任务:包括从电影评论中提取的句子以及带有其情绪的人类标注,经过训练可用于单句子的情感分析是正面,负面还是中立;
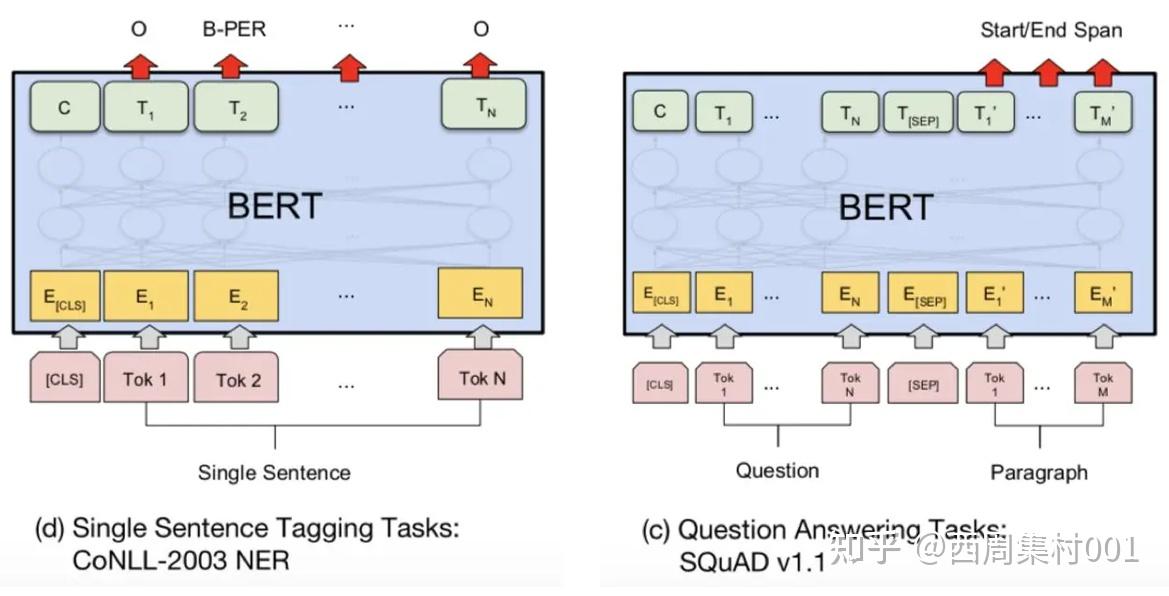
问答任务:任务中首先会有一个问题(question),有些问题可能是没有什么争议,看一篇文章就能回答,比如“世界第一高峰是什么”;而有些问题就没有那么容易,需要从多处找资料,然后还需要进行整理,比如“世界第一高峰比世界第二高峰高多少米?”,此时需要找到世界第一高峰的高度和世界第二高峰的高度,然后还要做一个减法;
单句子标注任务:单句子标注任务也叫命名实体识别任务,该任务是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等,以及时间、数量、货币、比例数值等文字。举个例子:“明朝建立于1368年,开国皇帝是朱元璋。介绍完毕!”那么我们可以从这句话中提取出的实体为:(1) 机构:明朝(2) 时间:1368年(3) 人名:朱元璋。
- 1.作为一种预训练模型,在特定场景使用时不需要用大量的语料来进行训练,节约时间效率高效,泛化能力较强。
- 2.Bert是一种端到端(end-to-end)的模型,不需要我们调整网络结构,只需要在最后加上特定于下游任务的输出层。
- 3.基于Transformer,可以实现快速并行,也可以增加到非常深的深度,充分发掘DNN模型的特性,提升模型准确率。
- 4.和ELMO,GPT等其他预训练模型相比,BERT是一种双向的模型,结合上下文来进行训练,具有更好的性能。
REF:BERT从零详细解读,看不懂来打我、图解BERT
如何计算Bert模型的参数量_bert参数量

打乱模型,让mask=真正的单词的概率最大

样本1、从同一个主题中取2个连续的段落作为正样本
样本2、从不同的主题中取2个段落/从同一个主题中取不连续的段落,作为负样本
下游业务有:单句子情感分析(NLP),双句子排序(NLP),问答(NLP),单句子序列标记(MLM)
Bert的输出数据组成是4部分,具体可以参考:bert 的输出格式详解
通过取Bert的输出结果的某部分+再结合比如全连接等操作,定制合适的模型。
比如本文的目标是实现文本分类,一共有10个类别,那么就是取Bert-output[1]这部分,它是Bert最后一层CLS-token的输出结果,它代表的是分类,而它的维度是最后一层隐藏层的维度大小(hidden_size)可能是768,那么可以再连接一个全连接层(输入:768,输出:10),实现10个分类。
REF:看这篇基于pytorch的bert文本分类的完整代码,但是这篇文章有几个地方需要修改,才能执行
- bert_model文件夹中的一个‘bert_config.json’复制一份改成‘config.json’,否则后面会报错模型中没有该json文件
- 奇怪的一点,一开始在jupyter导入包都会报错,在pycharm上可以导入包但是语句不行,再用jupyter后又都可以了
1)首先安装transformers库, 即:pip install transformers
2)然后下载预训练模型权重,参考REF里,下载好后,后面会调用这个模型文件创建预训练bert模型,当然也可以下载别的模型
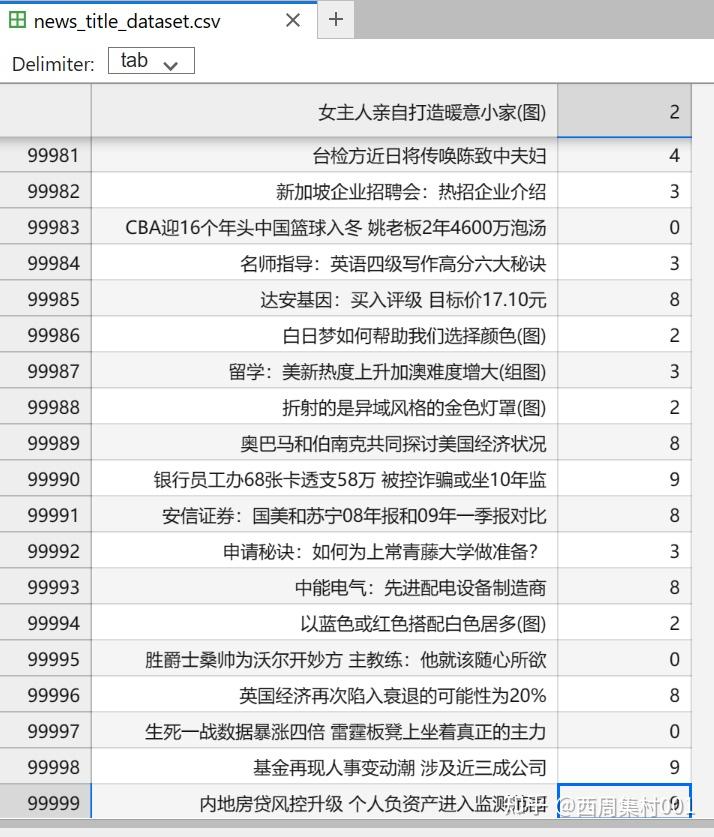
3)数据集素材下载,参考REF里,内容是10类新闻文本标题的中文分类问题(10分类)
下面正式写代码语句
A、先创建分词器
from transformers import BertTokenizer
bert_path = "bert_model/" # 下载的预训练模型放在这个文件夹中,该文件夹下存放三个文件('vocab.txt', 'pytorch_model.bin', 'config.json')
tokenizer = BertTokenizer.from_pretrained(bert_path)
# 备注下:vocab.txt,存放的是bert_中文这个模型下,中文的词库tips:BertTokenizer可以把句子做分词,也可以给整理成编码,可以参考:BertTokenizer 使用方法
test1:分词
sentence_demo="今天天气很不错"
words=tokenizer.tokenize(sentence_demo)
print(words)
---------------------------------------
输出
['今', '天', '天', '气', '很', '不', '错']test2:测试编码
sentence_demo="今天天气很不错"
words=tokenizer(sentence_demo)
print(words)
-----------------------------
输出:
{'input_ids': [101, 791, 1921, 1921, 3698, 2523, 679, 7231, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}可以看到句子中的每个字,都被编码encoding成汉字对应的index序列了。这个样式很像bert的3个输入。
test3:还可以根据编码的序列号,解码成对应的数据
sentence_decode=tokenizer.decode([101, 791, 102])
print(sentence_decode)
------------------------------------------------
输出:
[CLS] 今 [SEP]B、预处数据,整理出数据集
from tqdm import tqdm # tqdm是用于做滚动条的
import numpy as np
# tokenizer对句子编码后,会有3中数据: input char ids, segment type ids, attention mask
# 所以分别用3个变量来存起来
input_ids, input_masks, input_types, = [], [], []
labels = [] # 每一条数据都有一个对应的标签,对应也存储起来,和inpu_ids一 一对应起来,行称data-target
maxlen = 30 # 标题一般都很短,长度设置为30即可覆盖99%
with open("news_title_dataset.csv", encoding='utf-8') as f:
for i, line in tqdm(enumerate(f)):
title, y = line.strip().split('\t')
labels.append(int(y)) # 先把最简的 label存储起来
# encode_plus会输出一个字典,分别为'input_ids', 'token_type_ids', 'attention_mask'对应的编码
# 根据参数会短则补齐,长则切断
encode_dict = tokenizer.encode_plus(text=title, max_length=maxlen,
padding='max_length', truncation=True)
# 把每一个句子的编码数据,分别存放到大的集合中
input_ids.append(encode_dict['input_ids'])
input_types.append(encode_dict['token_type_ids'])
input_masks.append(encode_dict['attention_mask'])
# 本代码仅仅是测试一下代码流程,数据少点即可
if i>9980:
break
# 处理成nupmy数据
input_ids, input_types, input_masks = np.array(input_ids), np.array(input_types), np.array(input_masks)
labels = np.array(labels)
# 打印下句子被编码后的情况
print(input_ids.shape, input_types.shape, input_masks.shape, labels.shape)
-------------------------------------------------------------------------------------------------------
输出:
999it [00:00, 1269.82it/s]
(1000, 30) (1000, 30) (1000, 30) (1000,)一共是1002个句子,每个句子汉字数量固定设置为30个
- truncation=True, # 当句子长度大于max_length时,截断
- padding='max_length', 句子长度不足,则一律补零到max_length长度
- max_length=30,句子长度,汉字数量
- return_token_type_ids=True #返回token_type_ids
- return_attention_mask=True, #返回attention_mask
C、从数集中,切分出:训练集、验证集、测试集
# 生成一个numpy下标数据,并随机打乱索引
idxes = np.arange(input_ids.shape[0]) # input_ids.shape=(1000,30)
print("连续数据,打乱前,后10个下标情况:", idxes[:10])
np.random.seed(2019) # 固定种子,数值可以换,一次有效
np.random.shuffle(idxes) # 一般和seed(n)同时使用,这样每次都是打乱成一样
print("连续数据,打乱后,后10个下标情况:", idxes[:10])
# 8:1:1 划分训练集、验证集、测试集==800:100:100; 注意:只有numpy的数据和numpy的索引才可以如下操作
input_ids_train, input_ids_valid, input_ids_test = input_ids[idxes[:800]], input_ids[idxes[800:900]], input_ids[idxes[900:]]
input_masks_train, input_masks_valid, input_masks_test = input_masks[idxes[:800]], input_masks[idxes[800:900]], input_masks[idxes[900:]]
input_types_train, input_types_valid, input_types_test = input_types[idxes[:800]], input_types[idxes[800:900]], input_types[idxes[900:]]
# 同样,数据对应的label也要做同样的切分
y_train, y_valid, y_test = labels[idxes[:800]], labels[idxes[800:900]], labels[idxes[900:]]
print('训练的input_ids:',input_ids_train.shape, y_train.shape)
print('验证的input_ids:',input_ids_valid.shape, y_valid.shape)
print('测试的input_ids:',input_ids_test.shape, y_test.shape)
-------------------------------------------------------------------------------------------
输出:
连续数据,打乱前,后10个下标情况: [0 1 2 3 4 5 6 7 8 9]
连续数据,打乱后,后10个下标情况: [363 704 757 670 482 558 173 261 865 999]
训练的input_ids: (800, 30) (800,)
验证的input_ids: (100, 30) (100,)
测试的input_ids: (100, 30) (100,)import torch
from torch.utils.data import TensorDataset, DataLoader,RandomSampler,SequentialSampler
BATCH_SIZE = 16 # 小一点,示例用
# TensorDataset:用来打包数据
# LongTensor创建long64bit张量数据
# SequentialSampler 随机采样器,区别于顺序采样(SequentialSampler)
# 训练集数据打包
train_data = TensorDataset(torch.LongTensor(input_ids_train),
torch.LongTensor(input_masks_train),
torch.LongTensor(input_types_train),
torch.LongTensor(y_train))
train_sampler = RandomSampler(train_data)
train_loader = DataLoader(train_data, sampler=train_sampler, batch_size=BATCH_SIZE)
# 验证集数据打包
valid_data = TensorDataset(torch.LongTensor(input_ids_valid),
torch.LongTensor(input_masks_valid),
torch.LongTensor(input_types_valid),
torch.LongTensor(y_valid))
valid_sampler = SequentialSampler(valid_data)
valid_loader = DataLoader(valid_data, sampler=valid_sampler, batch_size=BATCH_SIZE)
# 测试集(是没有标签的)-数据打包
test_data = TensorDataset(torch.LongTensor(input_ids_test),
torch.LongTensor(input_masks_test),
torch.LongTensor(input_types_test))
test_sampler = SequentialSampler(test_data)
test_loader = DataLoader(test_data, sampler=test_sampler, batch_size=BATCH_SIZE)
print('训练数据_块数800/16:',len(train_loader))
print('验证数据_块数100/16:',len(valid_loader))
print('测试数据_块数100/16:',len(test_loader))
-------------------------------------------------------------------------------
输出:
训练数据_块数800/16: 50
验证数据_块数100/16: 7
测试数据_块数100/16: 7# 定义model
import torch.nn as nn
from transformers import BertConfig,BertModel
# Bert模型本身是已经封装很好的模型,并且有多种类型可以选择,此处:
# 1是通过下载的bert预训练模型,创建一个bert模型
# 2是将其再进一步调整封装下,主要是输出层,因为本篇文章的目的是文本分类,所以对其输出结果再进一步操作下
class Bert_Model(nn.Module): # 基本操作-继承基类nn.Module
def __init__(self, bert_path, classes=10): # 默认是10个分类,基于下载的与训练模型地址创建及初始化该类
super(Bert_Model, self).__init__()
self.config = BertConfig.from_pretrained(bert_path) # 导入下载好的预训练模型参数,确定好该模型的输出参数量,方便后面全连接层配置参数(输入-输出)
self.bert = BertModel.from_pretrained(bert_path) # 导入下好的预训练模型文件(加载预训练模型权重参数),创建模型,赋值给该类参数
self.fc = nn.Linear(self.config.hidden_size, classes) # 创建分类层,即全连接层,输入是bert模型的神经元参数总量,输出是10个类别
# print(self.config.hidden_size) # 3702/768
def forward(self, input_ids, attention_mask=None, token_type_ids=None): # 前馈网络,类模型,内部一层一层的计算过程
outputs = self.bert(input_ids, attention_mask, token_type_ids) # Bert模型的输入:三部分
out_pool = outputs[1] # out_puts是一个元组,outputs[0]代表第一个token即(cls)最后一层的隐藏状态 (batch_size, hidden_size
logit = self.fc(out_pool) # [bs, classes] 全连接优化参数(输出调成1个即可)
return logit几点说明:
1、output的输出形式是:一个元组类型的数据 ,包含四部分:
- last hidden state shape是(batch_size, sequence_length, hidden_size),hidden_size=768,它是模型最后一层的隐藏状态
- pooler_output:shape是(batch_size, hidden_size),这是序列的第一个token (cls) 的最后一层的隐藏状态,它是由线性层和Tanh激活函数进一步处理的,这个输出不是对输入的语义内容的一个很好的总结,对于整个输入序列的隐藏状态序列的平均化或池化可以更好的表示一句话。
- hidden_states:这是输出的一个可选项,如果输出,需要指定config.output_hidden_states=True,它是一个元组,含有13个元素,第一个元素可以当做是embedding,其余12个元素是各层隐藏状态的输出,每个元素的形状是(batch_size, sequence_length, hidden_size),
- attentions:这也是输出的一个可选项,如果输出,需要指定config.output_attentions=True,它也是一个元组,含有12个元素,包含每的层注意力权重,用于计算self-attention heads的加权平均值
2、本文的代码任务是文本分类(10个类别),所以只需要判定句子的第一个token即(cls)_最后一层的隐藏状态 (batch_size, hidden_size)的情况即可,原始的cls输出是hidde_size个情况,后续通过微调,即再跟一个全连接(输入:hidden_size,输出:10)即可。hidden_size--维度(说着称之为列的宽度)
补充一点:第一个token即(cls)-最后一层的隐藏状态,为啥是 (batch_size, hidden_size),分析的时候首先只考虑单句子,本质还是一个句子一个句子输入,1个句子有N个单词,经过处理后,每个单词的向量维度是hidden_size,那么从(1,N)->(N,hidden_size),经过若干隐藏层梳理后(最后一层隐藏层的维度是hidden_size),那么最终的输出的维度(宽度)必然也是hidden_size,所以一个句子的输出是(1,hidden_size),一个batch_size句子的输出是(batch_size,hidden_size)
3、回归到本篇文章,取bert输出结果的偏移量为1对应的CLS结果,对其进行后续加工处理
取一组数据测试下模型
# 数据准备
# 使用迭代器,一次取一个
data_iter = iter(train_loader)
ids, att, tpe, y = data_iter.__next__()
print('data_tensor.shape:',ids.shape) # batch_size=16,每个句子是30个词
# 实例化又给模型
model = Bert_Model(bert_path)
output=model(ids, att, tpe)
print(type(output))
print(output.shape)
print(output[0]) # 取其中一个句子对应的输出情况看看
# print(output)
-----------------------------------------------------------------------
输出:
data_tensor.shape: torch.Size([16, 30]) # batchsize=16,每个句子设置的长度是30
<class 'torch.Tensor'>
torch.Size([16, 10]) # 全连接处理后,输出结果的维度是10,代表10个类别
tensor([ 0.7316, -0.2753, -0.2667, -0.7355, -0.7434, -0.0118, -0.2225, 0.1584, 0.4589, -0.6775], grad_fn=<SelectBackward0>)
# 基于这个结果节可以计算出最大的概率是哪个,确定是哪个类了验证符合预期,下面开始训练
# 顺带打印下模型的参数情况看看
def get_parameter_number(model):
# 打印模型参数量
total_num = sum(p.numel() for p in model.parameters())
trainable_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
return 'Total parameters: {}, Trainable parameters: {}'.format(total_num, trainable_num)
print(get_parameter_number(model))
for i in model.parameters():
print(i.shape)输出
Total parameters: 102275338, Trainable parameters: 102275338
torch.Size([21128, 768])
torch.Size([512, 768])
torch.Size([2, 768])
torch.Size([768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([3072, 768])
torch.Size([3072])
torch.Size([768, 3072])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([3072, 768])
torch.Size([3072])
torch.Size([768, 3072])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([3072, 768])
torch.Size([3072])
torch.Size([768, 3072])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([3072, 768])
torch.Size([3072])
torch.Size([768, 3072])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([3072, 768])
torch.Size([3072])
torch.Size([768, 3072])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([3072, 768])
torch.Size([3072])
torch.Size([768, 3072])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([3072, 768])
torch.Size([3072])
torch.Size([768, 3072])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([3072, 768])
torch.Size([3072])
torch.Size([768, 3072])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([3072, 768])
torch.Size([3072])
torch.Size([768, 3072])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([3072, 768])
torch.Size([3072])
torch.Size([768, 3072])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([3072, 768])
torch.Size([3072])
torch.Size([768, 3072])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([3072, 768])
torch.Size([3072])
torch.Size([768, 3072])
torch.Size([768])
torch.Size([768])
torch.Size([768])
torch.Size([768, 768])
torch.Size([768])
torch.Size([10, 768])
torch.Size([10])DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Bert_Model(bert_path).to(DEVICE)
EPOCHS=1 # 本文仅仅是用于示例,所以只设置为1如果有GPU必须建议用上
criterion = nn.CrossEntropyLoss()from transformers import AdamW,get_cosine_schedule_with_warmup
optimizer = AdamW(model.parameters(), lr=2e-5, weight_decay=1e-4) #AdamW优化器
scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=len(train_loader),num_training_steps=EPOCHS*len(train_loader))
# AdamW它是 Adam 优化器的一种变体。它的作用是基于梯度更新神经网络的参数,使得损失函数最小化。
# 学习率先线性warmup一个epoch,然后cosine式下降。
# 这里给个小提示,一定要加warmup(学习率从0慢慢升上去),如果把warmup去掉,可能收敛不了。# 训练
import time
epoch=EPOCHS
device=DEVICE
criterion
for i in range(epoch):
"""训练模型"""
start = time.time()
model.train() # 进入训练模式
print("***** Running training epoch {} *****".format(i+1))
train_loss_sum = 0.0 #每一个epoch重置一下
for idx, (ids, att, tpe, y) in enumerate(train_loader):
ids, att, tpe, y = ids.to(device), att.to(device), tpe.to(device), y.to(device)
y_pred = model(ids, att, tpe)
loss = criterion(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step() # 学习率变化
train_loss_sum += loss.item()
if (idx + 1) % (len(train_loader)//5) == 0: # len(train_loader)//5=50/5=10,只打印5次结果
print("Epoch {:04d} | Step {:04d}/{:04d} | Loss {:.4f} | Time {:.4f}".format(
i+1, idx+1, len(train_loader), train_loss_sum/(idx+1), time.time() - start))
torch.save(model.state_dict(), "Model_Parameter_save/best_bert_model.pth")
--------------------------------------------------------------------------------------------------
输出:
***** Running training epoch 1 *****
Epoch 0001 | Step 0010/0050 | Loss 2.5034 | Time 28.7163
Epoch 0001 | Step 0020/0050 | Loss 2.3892 | Time 59.0213
Epoch 0001 | Step 0030/0050 | Loss 2.2982 | Time 89.0986
Epoch 0001 | Step 0040/0050 | Loss 2.2021 | Time 119.9282
Epoch 0001 | Step 0050/0050 | Loss 2.0588 | Time 151.8910基于现有设计好的带有标签的数据,对模型进行评估下准确性。
# 模型评估
from sklearn.metrics import accuracy_score
def evaluate(model, data_loader, device):
model.eval()
val_true, val_pred = [], [] # 关键就是那要拿到两个值_组成的列表:真实值列表、预测值列表
with torch.no_grad():
for idx, (ids, att, tpe, y) in (enumerate(data_loader)):
y_pred = model(ids.to(device), att.to(device), tpe.to(device))
y_pred = torch.argmax(y_pred, dim=1).detach().cpu().numpy().tolist()
val_pred.extend(y_pred)
val_true.extend(y.squeeze().cpu().numpy().tolist())
return accuracy_score(val_true, val_pred) #返回accuracy
device=DEVICE
model.eval()
acc = evaluate(model, valid_loader, device) # 验证模型的性能
print("current acc is {:.4f}".format(acc))预测的数据是没有标签的,但是它的标签信息在代码开始部分已经单独整理好了,可以直接拿来校验准确性
# 加载模型参数,对文本数据进行预测
from sklearn.metrics import classification_report
# 测试集没有标签,需要预测提交//但是测试集的真实标签,在代码开头,已经单独整理过,可以拿来用
def predict(model, data_loader, device):
model.eval()
val_pred = []
# 一般我们进行模型验证或者模型推理时,就不需要梯度以及反向传播,所以我们可以在torch.no_grad()上下文管理器中执行我们的验证或推理任务,可以显著降低显存的使用
with torch.no_grad():
for idx, (ids, att, tpe) in tqdm(enumerate(data_loader)): # 预测数据是没有标签分类的
y_pred = model(ids.to(device), att.to(device), tpe.to(device))
y_pred = torch.argmax(y_pred, dim=1).detach().cpu().numpy().tolist()
val_pred.extend(y_pred)
return val_pred
device=DEVICE
model.load_state_dict(torch.load("Model_Parameter_save/best_bert_model.pth"))
pred_test = predict(model, test_loader, DEVICE)
print("\n Test Accuracy = {} \n".format(accuracy_score(y_test, pred_test)))
print(classification_report(y_test, pred_test, digits=4))输出
Test Accuracy = 0.81
precision recall f1-score support
0 1.0000 1.0000 1.0000 12
1 1.0000 1.0000 1.0000 10
2 1.0000 0.8462 0.9167 13
3 1.0000 0.7778 0.8750 9
4 1.0000 0.2500 0.4000 8
5 1.0000 1.0000 1.0000 12
6 0.6000 1.0000 0.7500 6
7 0.7143 1.0000 0.8333 10
8 0.4211 1.0000 0.5926 8
9 1.0000 0.2500 0.4000 12
accuracy 0.8100 100
macro avg 0.8735 0.8124 0.7768 100
weighted avg 0.9011 0.8100 0.7937 100关于准确率/召回率等等指标的理解,参考:4.1 PyTorch:图像分类实战的4.10部分。
其它可参考连接:从0开始学bert、图解 | 深度学习:小白看得懂的BERT原理、保姆级教程,用PyTorch和BERT进行文本分类、bert 的输出格式详解
以上就是本篇文章【Bert模型的细节到底是怎么样的?】的全部内容了,欢迎阅览 ! 文章地址:http://www.uqian.cn/news/4366.html 资讯 企业新闻 行情 企业黄页 同类资讯 首页 网站地图 返回首页 极顶速云移动站 http://m.uqian.cn/ , 查看更多 点击拨打:
点击拨打: